- 1. What created the need for AI TRiSM?
- 2. How does AI TRiSM work?
- 3. What does the AI TRiSM architecture actually include?
- 4. How does AI TRiSM apply to models, applications, and agents?
- 5. Example AI TRiSM control flow
- 6. How to get started with implementing AI TRiSM
- 7. How is AI TRiSM different from responsible AI, AI governance, and AI security?
- 8. AI TRiSM FAQs
Table of contents
- What created the need for AI TRiSM?
- How does AI TRiSM work?
- What does the AI TRiSM architecture actually include?
- How does AI TRiSM apply to models, applications, and agents?
- Example AI TRiSM control flow
- How to get started with implementing AI TRiSM
- How is AI TRiSM different from responsible AI, AI governance, and AI security?
- AI TRiSM FAQs
A Guide to AI TRiSM: Trust, Risk, and Security Management
4 min. read
Table of contents
- What created the need for AI TRiSM?
- How does AI TRiSM work?
- What does the AI TRiSM architecture actually include?
- How does AI TRiSM apply to models, applications, and agents?
- Example AI TRiSM control flow
- How to get started with implementing AI TRiSM
- How is AI TRiSM different from responsible AI, AI governance, and AI security?
- AI TRiSM FAQs
AI TRiSM is a framework for managing AI systems trust, risk, and security through technical controls that enforce policies.
Developed by research and consulting firm Gartner, the framework inventories and risk-scores AI models, applications, and agents and maps the data they use.
It also performs continuous evaluation and inspects runtime behavior to detect policy violations, security threats, and unwanted outputs.
What created the need for AI TRiSM?
AI introduced risks that traditional controls were never designed to handle.
Models generate outputs, take actions, and process large context windows in ways that create new failure modes. Which means organizations now need controls that can assess and manage AI behavior directly.
A major driver is oversharing.
"Through 2026, at least 80% of unauthorized AI transactions will be caused by internal violations of enterprise policies concerning information oversharing, unacceptable use or misguided AI behavior rather than malicious attacks."
Most unauthorized AI activity comes from internal misuse, not malicious attacks. When data permissions are weak or inconsistent, AI systems can expose sensitive information faster than teams can react. Traditional data security tools were not built for this scale or speed.
Another factor is accuracy.
Enterprises struggle with unwanted or incorrect outputs that create legal, operational, and compliance risk. They need a way to evaluate those outputs in real time and block unsafe responses before they reach users.
Shadow AI made the problem worse.
- GenAI traffic surged more than 890% in 2024.
- In 2025, the average monthly number of GenAI-related data security incidents increased 2.5X, now comprising 14% of all data security incidents.
- Organizations saw on average 66 GenAI apps, with 10% classified as high risk.
Organizations sometimes deploy models, copilots, and agents without visibility or governance. In these situations, there's no consistent way to inventory AI systems, understand how they behave, or map the data they rely on.
In short: AI TRiSM emerged because enterprises need a unified framework that can see their AI, understand its risk, and control its behavior at runtime.
| Further reading:
- What Are AI Hallucinations? [+ Protection Tips]
- What Is Shadow AI? How It Happens and What to Do About It
- Agentic AI Security: What It Is and How to Do It
- What Is AI Governance?
Gartner Research: Market Guide for AI Trust, Risk and Security Management
Learn more about the TRiSM framework and market segment.
Download reportHow does AI TRiSM work?
AI TRiSM works by organizing the controls that govern AI systems into one structured model.
It brings together governance expectations, data protections, and runtime evaluation so they can be applied consistently across different models, applications, and agents. Functionally, this creates a single place to define how AI should operate and how its behavior should be checked.
The AI TRiSM framework uses three core ideas:
The first is clarity.
Organizations document their AI systems, the data they rely on, and the conditions under which they should be used. This information defines what “expected behavior” looks like.
The second idea is alignment.
Governance rules, data policies, and acceptable use requirements are connected so they are not handled in separate silos. That connection ensures that controls in later layers have the information they need to evaluate activity correctly.
The third idea is enforcement.
TRiSM ties documentation, access rules, and evaluation criteria to the points in the environment where AI interactions occur. This allows AI activity to be evaluated using the policies defined earlier and escalated when something looks risky.
To put this process into perspective, let's dig into the components AI TRiSM architecture includes.
Free AI risk assessment
Get a complimentary vulnerability assessment of your AI ecosystem.
Claim assessmentWhat does the AI TRiSM architecture actually include?

AI TRiSM works because it uses a layered architecture that turns high-level governance policies into real controls.
Each layer has a different job. Together, they create a system that understands what AI exists in the environment, evaluates the risk, and enforces the rules during every interaction.
TRiSM operates on top of existing traditional technology protections—such as network security, identity controls, data protection, and monitoring—which remain essential foundations but are not part of the TRiSM framework itself.
Let's walk through each layer so the structure is clear.
AI governance
The AI governance layer defines how an organization documents its AI systems and determines which controls they require.
It begins with a complete inventory of models, applications, and agents.
- Teams document what each system does, how it is used, and which data sources it relies on.
- They also assign an initial risk score so higher-risk systems receive the level of oversight they need.
Documentation is the next step.
- Teams capture model cards, bills of materials, and other records that describe how each system was built and how it should behave.
- These documents establish the baseline for evaluating future behavior.
- Governance tooling connects this documentation to approval workflows, change tracking, and the organization's control libraries.
This keeps reviews consistent and prevents AI systems from progressing without the right checks.
Continuous assurance ensures everything stays current.
- Evaluation results, drift indicators, and changes in risk profile trigger updated documentation or new review steps.
Which ensures governance is aligned with how each system performs after deployment.
| Further reading: What Is an AI-BOM (AI Bill of Materials)? & How to Build It
AI runtime inspection and enforcement
Runtime inspection and enforcement is where AI interactions are evaluated in real time.
This part of the framework relies on technical controls rather than manual review, and those controls are delivered through purpose-built AI security and policy enforcement tools. Practically speaking, this is where the organization's technology stack applies the rules defined earlier in governance.
Which is why the runtime inspection and enforcement layer is the core of TRiSM. It inspects every AI interaction and enforces enterprise rules in real time. Nothing else in the architecture provides this kind of immediate control.
It starts when an AI system receives a request.
- The request passes through policy engines that check the input, context, and generated output for issues such as data exposure, misuse, safety concerns, or unexpected behavior.
- Each engine produces a score for the type of risk it evaluates.
Those scores are then combined.
- A blended risk score gives reviewers a single view of the interaction's overall risk level.
- That score determines whether the result can be returned to the user, blocked, or sent to the appropriate team for review.
Single-pass processing keeps the workflow efficient.
- All relevant policy engines run at once rather than in separate stages.
- This avoids conflicting results and keeps interactions responsive.
Anomaly detection adds another layer of oversight.
It identifies unusual user behavior, unexpected model outputs, or actions from agents that fall outside their intended scope:
- High-confidence anomalies are blocked automatically. Lower-confidence issues are routed to the right people for investigation.
- Security events go to security operations.
- Compliance issues go to compliance teams.
- Acceptable-use concerns go to the groups responsible for misuse review.
Different AI systems require different controls.
- Models often need defenses against adversarial prompts or attempts to extract training data.
- Applications rely on context-aware access controls and output validation.
- Agents need checks that ensure their actions stay within their approved scope.
Information governance
The information governance layer defines which data AI systems can access and the conditions for that access.
It establishes the data boundaries that runtime enforcement relies on.
The work starts with understanding how information is stored and shared across the organization.
Data owners classify sensitive content, set access rules, and define retention requirements These decisions determine what an AI system should or should not be able to reach.
Important: runtime controls can only enforce what the data layer makes explicit.
Information governance also depends heavily on tooling.
- Discovery and classification tools identify where sensitive data lives.
- DSPM and DLP systems map exposure, detect oversharing, and apply controls that restrict how data is accessed.
- IAM and entitlement systems decide who can use which information and when.
Together, these tools give the organization a reliable picture of its data and the policies attached to it.
This matters because oversharing is one of the most common sources of AI risk.
If data is classified incorrectly or access rules are inconsistent, AI systems can surface information that users shouldn't see. And on its own, runtime enforcement can't compensate for unclear or incomplete data policies.
Infrastructure and stack
The infrastructure and stack layer provides the technical environment where AI systems run.
It includes the hosting platforms, execution sandboxes, and network pathways that support training, fine-tuning, and inference.
Infrastructure teams deploy controls that protect data and models while they are in use.
Trusted execution environments, isolation techniques, and secure hosting configurations reduce the attack surface and limit unauthorized access. Plus, these measures create the foundation that other TRiSM layers depend on.
API gateways manage how AI systems communicate with each other and with external services.
They enforce authentication, apply rate limits, and route traffic consistently so policy engines have the full context they need during runtime evaluation. Functionally, this ensures that controls defined in governance and enforced at runtime are applied to the right requests.
Auditability is another focus of this layer.
Infrastructure has to record state changes, system events, and interaction traces so investigations and compliance reviews have reliable evidence. These logs also give the organization a way to understand how AI systems behave over time.
Telemetry supports ongoing visibility.
It tracks performance, anomalies, and operational errors across environments. CI/CD pipelines integrate governance and runtime requirements so AI updates remain safe as they move from development to production.
Ultimately, the infrastructure and stack layer supplies the technical foundation that makes AI workloads reliable, observable, and enforceable.
It ensures that every control above it operates on systems that are secure, monitored, and configured to support policy-aligned AI behavior.
INTERACTIVE TOUR: PRISMA AIRS LAUNCH TOUR
See firsthand how Prisma AIRS secures models, data, and agents across the AI lifecycle.
Start tourHow does AI TRiSM apply to models, applications, and agents?
AI TRiSM applies its controls differently depending on whether the system is a model, an application, or an agent.
That's because each one behaves differently. Which means the risks look different. And the enforcement points do too.
| How TRiSM applies to models, applications, and agents |
|---|
| Entity | How it behaves | What TRiSM checks | Common failure pattern |
|---|---|---|---|
| Models | Take inputs, generate outputs, sit behind apps | Inputs, raw outputs, prompt injections, extraction attempts, unsafe or unwanted responses | Prompts trigger unexpected or incorrect outputs |
| Applications | Connect users to models and pull data from systems | What the app retrieves, whether data exposure is appropriate, output validation | Overshared or mis-permissioned data flows through the app |
| Agents | Run sequences of actions, call tools, make decisions | Action sequences, tool calls, alignment with intended scope, anomalous behavior | Agents take steps no one anticipated |
Models are the simplest place to start.
They take inputs. They produce outputs. And they sit behind the application layer.
TRiSM inspects those inputs and raw outputs before anything is formatted or presented to a user. For example, it looks for prompt injections, data extraction attempts, or outputs that fall outside a model's intended use. It also checks for unwanted behavior like hallucinations or unsafe responses.
This layer focuses on model correctness, safety, and resistance to misuse.
| Further reading: What Is a Prompt Injection Attack? [Examples & Prevention]
Applications sit a level higher.
They connect users to models and pull information from other systems. Which means they create different risks. Applications may expose too much data if permissions are loose or if context windows pull from overshared content.
Runtime inspection evaluates what the application retrieves and returns. It applies access controls, dynamic classification, and output validation.
The goal is simple: Make sure the application only uses the right information and only returns what the user is allowed to see.
Agents introduce the most complexity.
They run sequences of actions. They call tools. They make decisions that chain into more actions.
TRiSM checks whether those actions match the agent's intended scope. It monitors for anomalous behavior. For example, an agent that suddenly tries to access systems outside its task flow. When that happens the system blocks the action or redirects it for review.
Agents need alignment checks, action-level monitoring, and real-time enforcement because their behavior is dynamic.
Common failure patterns show why these distinctions matter:
- Models fail when prompts trigger unexpected outputs.
- Applications fail when overshared data flows through them.
- Agents fail when they take steps that no one anticipated.
Again, AI TRiSM addresses these failure modes by adjusting the controls to match each entity's behavior.
Example AI TRiSM control flow
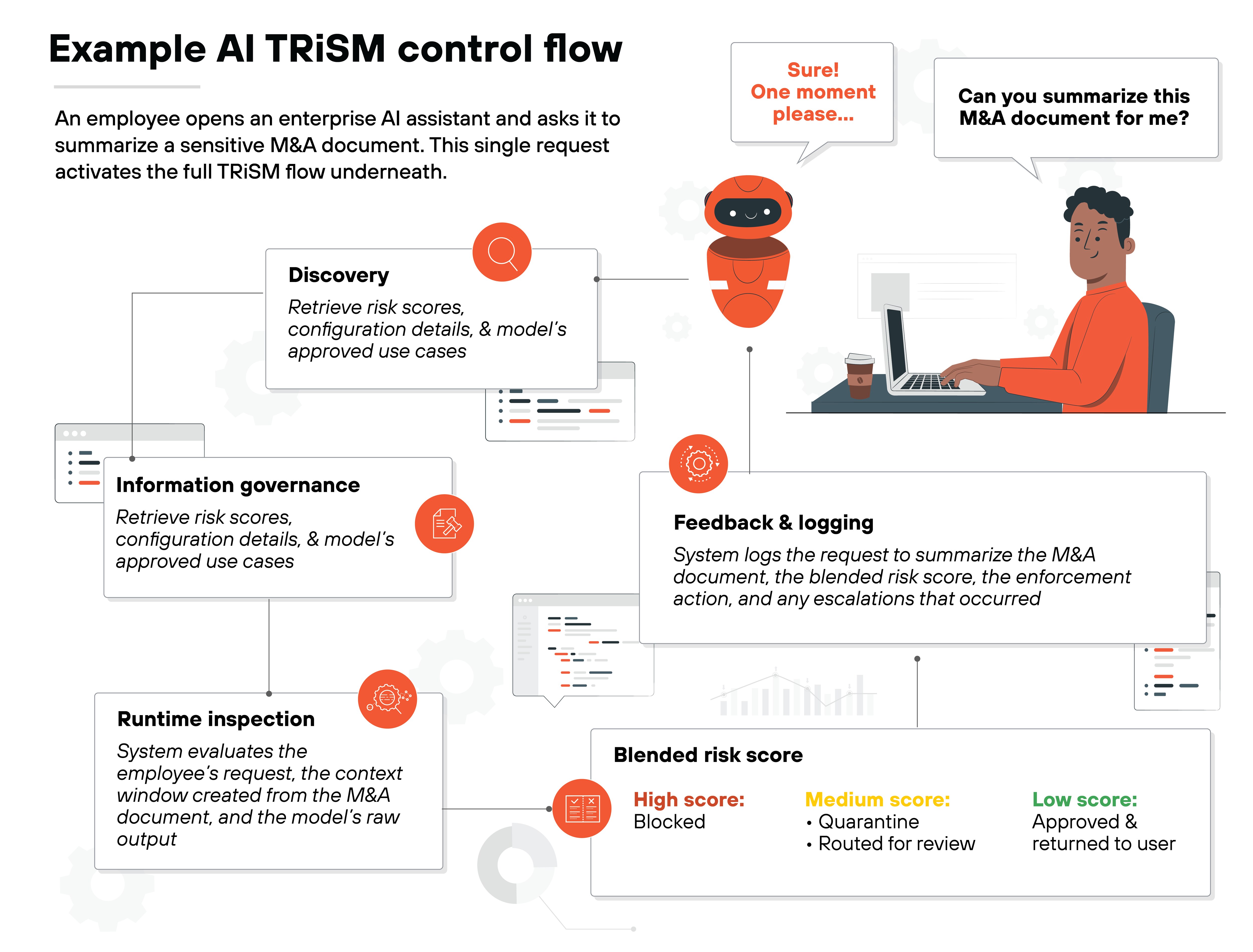
To show how AI TRiSM works when a real user interacts with a real system, let's take a look at an example of an end-to-end control flow.
It pulls every layer together. Which means this is where the architecture becomes something you can see.
Here's a simple scenario:
An employee opens an enterprise AI assistant and asks it to summarize a sensitive M&A document. This single request activates the full TRiSM flow underneath.
Let's break down how that would go:
The first step is discovery.
The system checks the AI catalog to identify the assistant that received the request and the model powering it. It retrieves the risk scores, configuration details, and the model's approved use cases, including any restrictions related to handling material nonpublic information found in documents like M&A summaries.
This gives the organization a baseline for what “normal” processing of highly sensitive transaction content should look like.
The next step is information governance.
The system checks the M&A document against the organization's data classifications and access rules, including any restrictions tied to material nonpublic information.
If the employee is not cleared to view transaction-related content, the request stops here. If the document is overshared or stored outside its approved repository—for example, if an M&A draft was uploaded to a general team folder—the system flags the violation and prevents the request from moving forward.
This ensures the model never processes deal-related information for users who do not have permission to see it.
Runtime inspection begins once the data checks pass.
The system evaluates the employee's request, the context window created from the M&A document, and the model's raw output.
Each policy engine examines this specific interaction for risks tied to handling material nonpublic information and generating a summary of deal-related content.
For example, one engine checks whether sensitive deal terms or financial details could leak through the summary. Another evaluates the output for hallucinations or reasoning errors that could misstate the transaction. Another looks for unacceptable or unsafe content that may violate internal policy or regulatory expectations.
Each engine produces a score.
The system evaluates the employee's request, the context window created from the M&A document, and the model's raw output.
Which means the system needs a blended risk score so it can evaluate this specific M&A summary request as one event rather than a set of separate checks. This combined score determines how the organization should handle the output.
Here's how that decision plays out:
High score → Blocked
Medium score → Quarantined → Routed for review:
- Data issues → information governance
- Security issues → security operations
- Compliance issues → legal or compliance
Low score → Approved and returned to the user
The final step is feedback.
The system logs the request to summarize the M&A document, the blended risk score, the enforcement action, and any escalations that occurred.
Those records support continuous assurance by giving governance teams real examples of how deal-related information is being used, which helps them refine policies, update documentation, or adjust controls when actual interactions reveal new risks.
Here's the takeaway:
This example shows one way a single AI request can move through TRiSM's core functions: inventory checks, data controls, runtime evaluation, and continuous assurance. It illustrates how the framework's components work together to shape AI behavior in practice.
How to get started with implementing AI TRiSM

The prior section was all about how TRiSM works during a single request. Now let's shift to how organizations can begin putting TRiSM into practice.
Implementing AI TRiSM works best when it starts small and grows in deliberate steps.
The goal isn't to deploy every control at once. It's to build a foundation that makes the rest of the framework effective.
The first step is strengthening information governance.
This is about fixing the data layer before touching the AI layer.
Overshared or poorly classified data breaks TRiSM because runtime controls cannot enforce rules if the underlying permissions are wrong.
Start by improving classification, cleaning up access, and reducing broad exposure.
The next step is discovering the AI already in use.
Most organizations have models, applications, and agents scattered across teams.
Inventory them. Document how they work. And assign a baseline risk score so high-risk systems get attention first.
From there, build an AI catalog.
The catalog anchors TRiSM because it organizes AI entities, their owners, and the data they rely on. It defines what “normal” behavior looks like.
This context is required for runtime enforcement to make safe decisions.
Once the catalog is in place, deploy runtime inspection for the highest-risk interactions.
Start with systems that touch sensitive data or external AI services.
Runtime controls evaluate each interaction, generate blended risk scores, and block or escalate risky behavior.
Starting small keeps enforcement manageable and avoids slowing teams down.
The final step is aligning responsibilities.
TRiSM spans security, data governance, compliance, legal, AI engineering, and the business.
Each escalation path must be clear so runtime events reach the right team without confusion.
In compact form: Fix the data foundation, build the catalog, apply runtime controls where risk is concentrated, and align teams early.
Taking a phased approach helps operationalize AI TRiSM without overextending workflows.
How is AI TRiSM different from responsible AI, AI governance, and AI security?
AI TRiSM is often confused with responsible AI, governance, and security, and that overlap can make it harder for organizations to understand where operational controls fit.
Each discipline focuses on a different part of the problem. And that means the boundaries matter.
Here's a clear way to separate them:
| How AI TRiSM differs from responsible AI, AI governance, and AI security |
|---|
| Discipline | What it focuses on | How it differs from AI TRiSM |
|---|---|---|
| Responsible AI | Ethical principles and high-level values such as fairness, transparency, and accountability. | Responsible AI defines what should happen. AI TRiSM enforces what must happen by applying policies and detecting violations during AI interactions. |
| AI governance | Policies, approvals, documentation, workflows, and oversight across the AI lifecycle. | Governance sets expectations and manages process-level compliance. AI TRiSM operationalizes those expectations through cataloging, risk scoring, continuous evaluation, and runtime enforcement. |
| AI security | Protecting AI models, applications, data, and pipelines from threats, misuse, and unauthorized access. | Security focuses on threats and vulnerabilities. AI TRiSM blends those signals with governance requirements and applies risk-based controls at the moment of interaction. |
At a high level, these domains work together, but AI TRiSM is the control layer that applies their requirements in real time.
Personalized demo: Prisma AIRS
Schedule a personalized demo with a specialist to see how Prisma AIRS protects your AI models.
Book demoAI TRiSM FAQs
AI TRiSM is a framework that manages the trust, risk, and security of AI systems. It inventories AI entities, maps their data, evaluates them continuously, and applies runtime controls to enforce organizational policies and detect violations during AI interactions.
An employee requests a summary of a sensitive document. AI TRiSM checks data permissions, references the AI catalog, evaluates the interaction with policy engines, generates a blended risk score, and then allows, blocks, or escalates the output based on organizational rules.
AI TRiSM was defined by Gartner as a structured framework for trust, risk, and security management across AI models, applications, and agents.