- 1. Why is AI model security important?
- 2. How does AI model security work?
- 3. What are the main threats to AI models?
- 4. How do AI model attacks happen?
- 5. How to protect against AI model attacks
- 6. Which frameworks and standards guide AI model security?
- 7. What does the future of AI model security look like?
- 8. AI model security FAQs
Table of contents
- Why is AI model security important?
- How does AI model security work?
- What are the main threats to AI models?
- How do AI model attacks happen?
- How to protect against AI model attacks
- Which frameworks and standards guide AI model security?
- What does the future of AI model security look like?
- AI model security FAQs
AI Model Security: What It Is and How to Implement It
5 min. read
Table of contents
- Why is AI model security important?
- How does AI model security work?
- What are the main threats to AI models?
- How do AI model attacks happen?
- How to protect against AI model attacks
- Which frameworks and standards guide AI model security?
- What does the future of AI model security look like?
- AI model security FAQs
AI model security is the protection of machine learning models from unauthorized access, manipulation, or misuse that could compromise integrity, confidentiality, or availability.
It focuses on safeguarding model artifacts and controlling how models are trained, deployed, and queried.
AI model security ensures models function as intended by preventing attacks that alter behavior, extract proprietary information, or expose sensitive training data.
Why is AI model security important?
AI models now sit at the center of decision-making in nearly every industry. They flag fraud, filter medical scans, and automate supply chains. As that dependence grows, so does the incentive to exploit them.
88% of organizations now use AI in at least one function, yet most remain in pilot phases, according to McKinsey's survey, The state of AI in 2025: Agents, innovation, and transformation. This suggests that many models are exposed before governance or monitoring fully mature.
Plus, corporate AI investment topped $252.3 billion last year as stated by Stanford University's HAI Artificial Intelligence Index Report 2025. And that makes risks like model theft and tampering not just technical, but material business risks.
Attackers target models for three main reasons:
- They hold proprietary algorithms and training data that carry commercial value.
- They run continuously and make real-time decisions that can be influenced.
- And unlike source code, their behavior can be probed through normal queries—no breach required.
When a model is compromised, the impact spreads fast.
A poisoned fraud-detection system might start approving risky transactions. A cloned recommendation engine can leak customer data or power a competing service. Even subtle manipulations can undermine trust in automated decisions that organizations rely on daily.
Not to mention, the attack surface is expanding beyond traditional deployments.
Cloud-hosted machine learning, open-source model reuse, and federated training all introduce new exposure points. Each adds interfaces where models, data, and updates can be intercepted or tampered with.
That's where AI model security comes in.
It gives organizations visibility into where models reside, how they behave, and whether they've been altered. Discovery, posture management, and runtime protection form a continuous process that keeps models stable, accountable, and secure.
In short: as AI becomes more embedded in operations, protecting the models themselves has become as essential as protecting the infrastructure they run on.
FREE AI RISK ASSESSMENT
Get a complimentary vulnerability assessment of your AI ecosystem.
Claim assessmentHow does AI model security work?
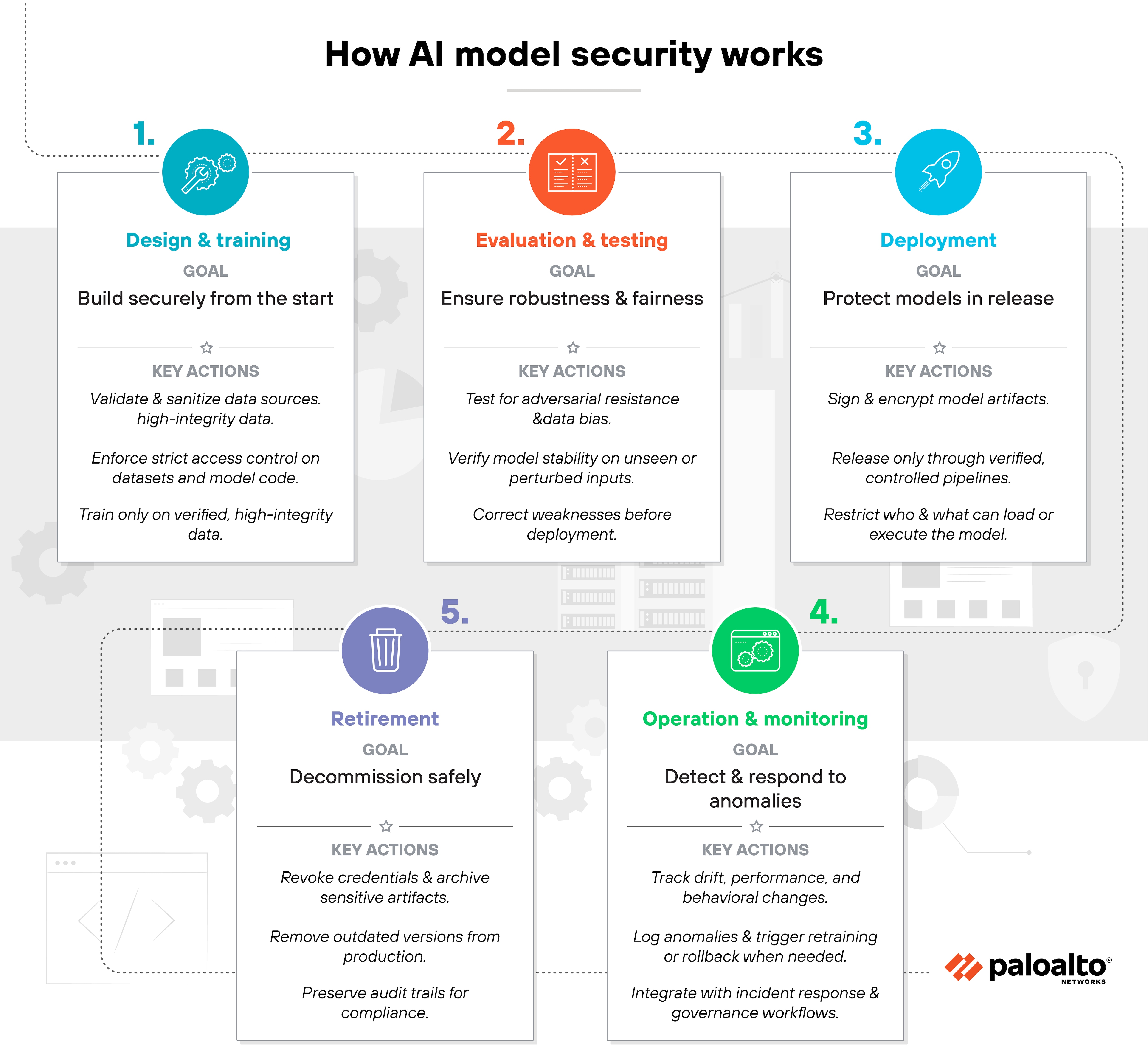
AI model security works by protecting models across their entire lifecycle.
From the moment data is collected to when a model is retired, each stage introduces unique risks. Securing those stages ensures that models remain reliable, explainable, and trustworthy in production.
It starts with design and training.
Data is validated, sanitized, and verified for authenticity before use. Strong access controls limit who can modify datasets or model code. That means training only occurs on approved, high-integrity data from known sources.
Next comes evaluation and testing.
Models are tested for robustness against adversarial inputs and checked for fairness and bias. If a model can be tricked or produces skewed results, it's corrected before deployment. Testing also verifies that model performance doesn't depend on hidden or unstable patterns in the data.
During deployment, security focuses on protection and integrity.
Models are signed, encrypted, and released through controlled pipelines. Only authorized systems can load or run them. This prevents tampering or replacement with unverified versions.
Once in production, operation and monitoring take over.
Continuous telemetry tracks how models behave, how predictions shift, and whether data drift occurs. Anomalies are logged, reviewed, and, when necessary, trigger retraining or rollback. This stage connects directly to incident response and governance processes.
Finally, models enter retirement.
Old or unused versions are decommissioned, credentials are revoked, and sensitive artifacts are archived securely. It's the same discipline applied to any critical asset lifecycle. Only here, the asset learns and changes over time.
In practice, AI model security fits naturally into machine learning pipelines and broader enterprise risk programs. It builds consistency between data science, engineering, and security teams to keep every model resilient from creation to retirement.
What are the main threats to AI models?
' with text stating that tiny input changes cause incorrect predictions or misclassification. In the bottom row, the fifth icon shows a magnifying glass above the label 'Membership inference' with text about determining whether specific data points were in the training set. The sixth icon displays a gear with a small alert symbol above the label 'Model reprogramming / backdoors' with text describing hidden triggers that cause unintended or malicious behavior. The seventh icon shows a chat bubble above the label 'Prompt injection / data leakage (GenAI)' with text explaining that malicious prompts override instructions or extract hidden information.")
AI models face a growing set of attacks that exploit how they learn, store, and respond to data. These threats target every part of the model lifecycle — from training to deployment — and can affect accuracy, reliability, and trust.
Understanding them helps teams recognize where controls are most critical.
Model extraction / theft: Attackers steal a model's logic or parameters by observing its outputs. They send repeated queries through public or internal APIs to reconstruct the model, often gaining access to valuable intellectual property or proprietary insights without breaching the underlying system.
Model inversion: In this attack, adversaries reconstruct sensitive information from a model's predictions. By analyzing repeated outputs, they can infer private training data such as images, health records, or user attributes that were never meant to be revealed.
Model poisoning: Poisoning manipulates a model during training by injecting corrupted or biased data. Even small changes in training samples can degrade accuracy, introduce backdoors, or steer decisions toward an attacker's desired outcome.
| Further reading: What Is Data Poisoning? [Examples & Prevention]Adversarial examples (evasion): Small, almost invisible changes to input data can cause a model to misclassify or misinterpret results. For example, adding subtle noise to an image can make a traffic sign classifier read “stop” as “speed limit.” These attacks exploit how sensitive models are to slight perturbations in input.
Membership inference: This attack determines whether specific data points were used in training. It can expose whether an individual's personal information contributed to a model and, by extension, leak private or regulated data.
Model reprogramming / backdoors: Attackers modify models to behave in unintended ways. They embed hidden triggers that activate malicious or unauthorized behavior when specific inputs appear, often bypassing normal testing and validation.
Prompt injection / data leakage (for GenAI): For generative AI, attackers craft malicious prompts that override system instructions or extract hidden information. These injections can lead to data exposure, reputational harm, or unwanted actions performed by the model itself.
| Further reading: What Is a Prompt Injection Attack? [Examples & Prevention]
In short: each threat exploits a different weakness in how models are built or used. Together, they underscore why AI model security must combine data protection, continuous testing, and ongoing behavioral monitoring to maintain safe and trustworthy performance.
How do AI model attacks happen?
AI model attacks don't happen in a vacuum. They depend on where the model lives and how it's accessed. Different deployment environments create different paths for exploitation.
Understanding these contexts helps explain why no single defense can cover every risk.
| AI model attack vectors by deployment environment |
|---|
| Environment | Primary attack vector | Target | Typical impact |
|---|---|---|---|
| Cloud | Query-based extraction and inversion via APIs | Model parameters and training data | IP theft, data leakage |
| Edge | Side-channel access and tampering | Model binaries and weights | Compromise of device integrity |
| Federated | Gradient leakage and poisoning | Shared model updates | Biased or corrupted global models |
Cloud environments
Most cloud-based attacks occur through exposed application programming interfaces (APIs).
Attackers can query hosted models repeatedly to infer their logic, recover parameters, or rebuild an approximation — a process known as model extraction.
They can also perform model inversion, using a model's responses to reconstruct sensitive data from its training set.
In managed machine learning services, or MLaaS, these risks are amplified when models return detailed confidence scores or are shared across tenants without strict isolation.
Access control and output filtering reduce exposure, but monitoring query patterns remains the best indicator of active extraction attempts.
Edge environments
Edge deployments introduce physical attack surfaces.
Models running on local or embedded devices can be targeted through side-channel analysis — measuring power use, timing, or electromagnetic (EM) emissions to infer model weights or internal operations.
Attackers with physical access can also clone or modify model binaries directly, bypassing centralized controls.
Because edge devices often operate in constrained or disconnected conditions, patching and remote validation are harder.
Securing these environments requires hardware-level protections, such as secure enclaves, tamper detection, and encrypted model execution.
Federated learning environments
Federated learning allows multiple participants to train a shared model without exchanging raw data.
However, it opens new opportunities for insider or participant-level attacks.
Malicious clients can poison shared gradients to bias global results, or perform gradient inversion to recover sensitive data from peers.
Even partial information leakage can undermine privacy guarantees and model reliability.
Effective countermeasures include secure aggregation, anomaly detection, and participant reputation scoring.
Hybrid and multi-cloud deployments often combine these risks.
When models move between cloud, edge, and collaborative systems, attack surfaces overlap — creating complex scenarios where data, code, and trust boundaries all blur.
That's why securing AI models requires environment-specific controls working together across the full lifecycle.
How to protect against AI model attacks

AI model attacks surface in different ways.
Some show up as strange predictions. Others slip in during training. And some target the model directly through probing or tampering.
Which means that protecting AI models requires three things at once: detecting attacks early, limiting their impact, and preventing them from recurring.
Here's how to approach it in practice:
Detection
Early detection is the difference between a small incident and a cascading failure.
-
Monitor model behavior continuously
- Track accuracy, confidence scores, and class distributions over time.
- Flag sudden changes or drift in predictions.
- Compare outputs against clean validation sets to detect poisoning or degradation.
-
Watch for extraction or probing patterns
- Monitor query volume, input diversity, and repetitive probing sequences.
- Rate-limit or sandbox suspicious API usage.
- Look for queries designed to map decision boundaries.
Tip:Track the ratio of unique inputs to repeated inputs over time. Abrupt increases in highly varied or systematically structured queries often signal boundary-mapping activity linked to model extraction attempts. -
Verify model integrity
- Use checksums or cryptographic signatures at load time.
- Alert on unauthorized weight changes or unapproved model versions.
Mitigation
When a threat is confirmed—or strongly suspected—the priority is to contain disruption and preserve trust.
-
Isolate affected components
- Remove compromised training data or corrupted model versions.
- Disable or restrict high-risk endpoints until investigation completes.
-
Roll back to verified models
- Restore from a signed, validated checkpoint.
- Avoid continuing training from a compromised state.
- Re-run robustness and fairness tests before redeployment.
-
Limit downstream exposure
- Add human review to sensitive outputs.
- Disable automation paths that rely on the affected model.
- Notify internal teams of temporary limitations.
Tip:Temporarily isolate any upstream systems that feed the model new data. This prevents compromised inputs or retraining triggers from reinforcing the attack while the investigation is underway.
Prevention
The strongest protection is stopping attacks before they reach the model.
-
Secure the training pipeline
- Enforce strict data provenance and authenticated data ingestion.
- Validate datasets with automated quality, anomaly, and consistency checks.
- Sign and verify all artifacts, dependencies, and containers.
-
Harden the model itself
- Apply techniques like information-theoretic perturbation to reduce extraction risk.
- Use differential privacy when appropriate to protect training data.
- Embed watermarks or fingerprints to detect theft or unauthorized reuse.
-
Protect the model at runtime
- Require authentication and authorization for all inference endpoints.
- Use rate limiting to slow down extraction attempts.
- Apply encrypted inference selectively where confidentiality matters most.
-
Strengthen system-level resilience
- Use supply-chain attestation to ensure models and artifacts originate from trusted sources.
- Run recurring AI red teaming to uncover weaknesses before attackers find them.
- Maintain a mature rollback and incident response plan.
| Further reading:
- What Is an AI-BOM (AI Bill of Materials)? & How to Build It
- What Is AI Red Teaming? Why You Need It and How to Implement
- How to Secure AI Infrastructure: A Secure by Design Guide
INTERACTIVE DEMO: PRISMA AIRS
See firsthand how Prisma AIRS secures models, data, and agents across the AI lifecycle.
Launch demo
Which frameworks and standards guide AI model security?
AI model security doesn't exist in isolation.
It's built on a growing body of frameworks that help organizations manage risk, strengthen controls, and create accountability. Each standard contributes a different piece: governance, engineering, adversarial testing, or operational assurance.
Together, they form the foundation for securing models throughout their lifecycle.
| AI model security frameworks |
|---|
| Framework / Standard | Focus area | Lifecycle alignment | Key contribution |
|---|---|---|---|
| NIST AI Risk Management Framework | Risk governance and control mapping | Govern / Operate | Defines a repeatable process to map, measure, and manage AI risk across systems and teams |
| MITRE ATLAS | Adversarial tactics, techniques, and mitigations | Design / Operate | Catalogs real-world AI attack methods and countermeasures for model hardening and red teaming |
| ISO/IEC 42001:2023 | AI management system requirements | Govern | Establishes organizational policies, oversight roles, and continuous improvement practices for AI governance |
| ISO/IEC 5338:2023 | AI lifecycle engineering and development | Design / Train / Deploy | Outlines secure-by-design principles for developing and maintaining AI systems responsibly |
| OWASP Machine Learning Security Top Ten | Common security risks and vulnerabilities in machine learning systems | Train / Deploy / Operate | Outlines ten prevalent ML security issues—including input manipulation, data poisoning, model theft, inversion, and supply chain attacks—and provides prevention techniques and best practices for developers and MLOps teams |
These frameworks were developed independently but address complementary aspects of AI assurance.
One emphasizes governance and risk management, another focuses on engineering and lifecycle controls, and others map adversarial techniques or technical vulnerabilities.
Used together, they provide a broader foundation for securing AI models, from development through deployment and ongoing operation.
The result is a more consistent and auditable approach to AI security that aligns technical practice with organizational accountability.
| Further reading:
What does the future of AI model security look like?

AI model security is moving into a new phase.
The first wave focused on basic hardening: encrypting models, validating data, and monitoring for drift.
Now, the discipline is shifting toward active assurance, where protection is built into how models train, learn, and interact.
The next phase will emphasize continuous verification.
Early defenses like watermarking and fingerprinting helped prove model ownership, but attackers are learning to bypass them. Future systems will combine cryptographic proofs with live telemetry, letting models authenticate themselves through behavior rather than static tags.
Security will also evolve to match the complexity of multimodal and generative AI.
As models learn from text, image, and video together, poisoning can cross domains in ways traditional checks can't detect. That's driving research into automated validation pipelines—tools that scan incoming data and retraining events for subtle manipulation before it reaches production.
At the same time, testing itself is becoming autonomous.
AI-driven red teaming and simulation frameworks will continuously probe models for weaknesses, mimicking adversarial behavior at machine speed. Defenders won't just react to incidents. They'll run constant self-assessment loops that adapt as models evolve.
Finally, quantum computing looms as both a risk and catalyst.
Its power could weaken today's encryption, pushing AI security toward quantum-safe and hybrid cryptographic protections well before the threat becomes mainstream.
Current trends suggest AI model security will become more self-managing and aligned with emerging regulations. Which is a shift from static compliance to dynamic assurance.
Models won't just need to perform accurately. They'll need to prove, continuously, that they're operating securely and as intended.
PERSONALIZED DEMO: PRISMA AIRS
Schedule a personalized demo with a specialist to see how Prisma AIRS protects your AI models.
Book demo
AI model security FAQs
Behavioral anomalies often signal compromise: unexpected predictions, accuracy drops, or output drift. Continuous monitoring, checksum verification, and audit logs can confirm unauthorized changes. Comparing live model behavior against validated baselines helps detect tampering or data poisoning before it propagates across production systems.
Tracing depends on proactive ownership controls. Watermarking or fingerprinting embedded during development can verify provenance if a stolen model resurfaces. Actual recovery is rare, but detection enables legal or technical response, including takedown, revocation, or retraining from secured, documented source versions.
Retraining on poisoned or manipulated data amplifies the damage. The model reinforces false correlations, spreads bias, and degrades reliability. Secure data provenance, signed artifacts, and retraining governance prevent attackers from continuously influencing weights or parameters through incremental updates.
They aren’t automatically insecure but expose greater risk. Public availability of weights and architectures lowers the barrier for cloning, modification, or targeted attacks. Security depends on maintaining trusted repositories, validating contributions, and limiting use of external models without provenance verification or vulnerability assessment.
Yes. Research points toward autonomous assurance, which means models capable of self-testing, behavioral validation, and continuous compliance reporting. Automated red teaming, runtime telemetry, and adaptive defense loops will allow AI systems to monitor integrity and enforce security requirements without manual intervention.