- 1. Why is data security management important?
- 2. What is the CIA Triad's role in data security management?
- 3. What tools, controls, and technologies support data security management?
- 4. How to manage data security across the full data lifecycle
- 5. How to implement data security management step-by-step
- 6. What frameworks guide data security management?
- 7. Who owns data security management in an organization?
- 8. Top 5 common data security management pitfalls
- 9. Comparing data security management, information security management, and cybersecurity management
- 10. Data security management FAQs
Table of contents
- Why is data security management important?
- What is the CIA Triad's role in data security management?
- What tools, controls, and technologies support data security management?
- How to manage data security across the full data lifecycle
- How to implement data security management step-by-step
- What frameworks guide data security management?
- Who owns data security management in an organization?
- Top 5 common data security management pitfalls
- Comparing data security management, information security management, and cybersecurity management
- Data security management FAQs
What Is Data Security Management? How to Manage Data Security
5 min. read
Table of contents
- Why is data security management important?
- What is the CIA Triad's role in data security management?
- What tools, controls, and technologies support data security management?
- How to manage data security across the full data lifecycle
- How to implement data security management step-by-step
- What frameworks guide data security management?
- Who owns data security management in an organization?
- Top 5 common data security management pitfalls
- Comparing data security management, information security management, and cybersecurity management
- Data security management FAQs
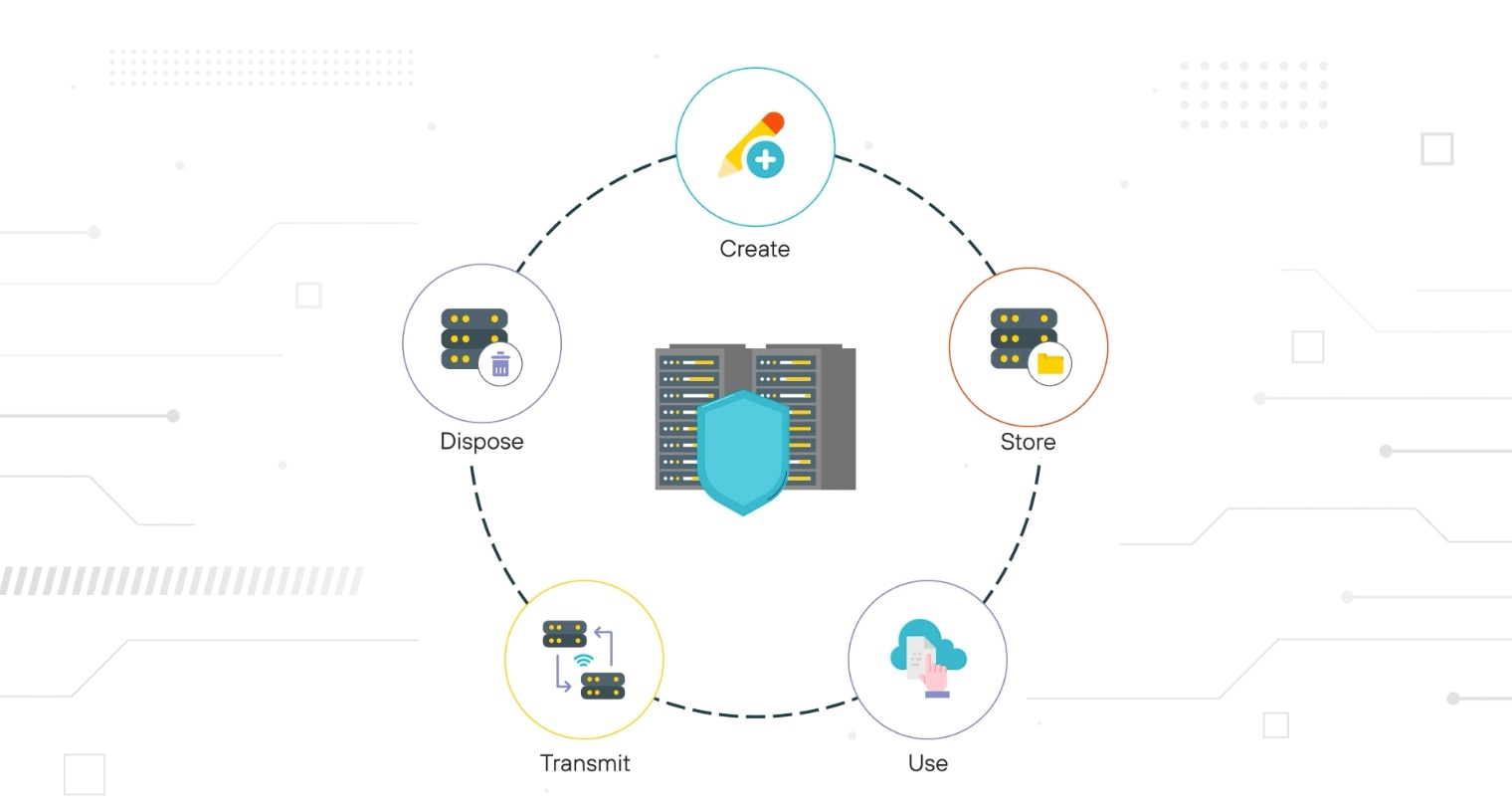
Data security management is the practice of protecting data from unauthorized access, alteration, or loss throughout its lifecycle. It includes the development and enforcement of policies, processes, and controls that ensure data remains secure during creation, storage, use, and disposal.
Effective data security management aligns technical safeguards with organizational oversight to reduce risk and support compliance.
Why is data security management important?
Data security management is important because it creates a consistent, organization-wide approach to protecting sensitive data.
Without it, security controls are often uneven, reactive, or incomplete. Especially as data environments grow more complex.
Most organizations operate in hybrid environments and rely on external providers for infrastructure, storage, and collaboration. Data is constantly being accessed, modified, shared, and stored across systems and teams.
"92% of workloads are now hosted on some form of cloud platform, indicating a significant shift from traditional on-premises solutions. Only 8% of workloads remain solely on-premises, showing a substantial move towards cloud-based infrastructure across various industries."
In many cases, no single group has full visibility or authority over how that data is handled. That makes it harder to identify weak points. And easier for something to go wrong.
Here's where data security management makes a difference:
It gives structure to how data protection is planned and enforced. That includes how data is classified, who can access it, how it's monitored, and what happens if it's lost or exposed.
It also establishes accountability. Different roles—from security teams to business units—understand what they're responsible for and how their actions impact data risk.
And the cost of getting it wrong keeps rising.
IBM’s 2025 Cost of a Data Breach Report found the global average cost of a data breach reached $4.44 million per incident. In the United States, the average was more than double at $10.22 million.
This kind of clarity helps reduce the likelihood of mistakes, misconfigurations, and missed threats.
It also makes it easier to meet compliance requirements, investigate incidents, and recover faster when needed.
In short, data security management moves data protection from a patchwork of efforts to a coordinated, measurable program.
| Further reading: What Is Data-Centric Security?
What is the CIA Triad's role in data security management?
The CIA Triad refers to three core principles:
- Confidentiality
- Integrity
- Availability

These principles are used to evaluate and enforce the protection of data across its lifecycle. Data security management uses them as the foundation for how safeguards are planned, applied, and measured.
Confidentiality focuses on limiting access to data based on need and risk. It prevents unauthorized exposure through controls like authentication, encryption, and role-based access.
Integrity ensures that data remains accurate and complete. That includes protecting it from unauthorized changes and validating that it hasn't been tampered with.
Availability ensures that data remains usable when needed. This requires resilient systems, backup plans, and monitoring to reduce downtime and service disruption.
Why does this matter?
Because data security controls are only effective when they address all three areas. Overemphasizing one—like confidentiality—without considering availability or integrity can introduce new risks.
The CIA Triad provides a balanced framework that helps organizations protect data in practical, measurable ways.
It also supports clearer decisions when classifying data, assigning protections, and responding to incidents.
What tools, controls, and technologies support data security management?
', 'Identity providers (IdPs)', 'Cloud access security brokers (CASBs)', 'Endpoint detection & response (EDR)', 'Backup & recovery software', and 'Security information & event management (SIEM)'. From the Technologies circle, six items branch outward: 'Public key infrastructure (PKI)', 'Transport layer security (TLS)', 'Tokenization', 'Federated identity', and 'Zero trust architectures'. Below the central Controls circle, six vertical items are listed: 'Encryption', 'Data classification', 'Access control', 'Segmentation', 'Audit logging', and 'Monitoring & alerting'. All elements are organized in a clean, symmetrical diagram under the title 'Data security management tools, controls, & technologies'.")
Data security management relies on a wide range of tools, controls, and technologies that work together to protect data across its lifecycle.
Here's how to break it down:
Tools
These are the systems and platforms used to enforce policies, monitor activity, and respond to risks.
- Data loss prevention (DLP): Blocks unauthorized sharing or transfer of sensitive data
- Security information and event management (SIEM): Collects and analyzes logs to detect and alert on threats
- Cloud access security brokers (CASBs): Enforce data security policies across SaaS applications
- Endpoint detection and response (EDR): Monitors endpoints for signs of compromise
- Identity providers (IdPs): Manage authentication and enable single sign-on
- Backup and recovery software: Restores data after accidental loss or corruption
Controls
Controls are the safeguards—administrative, technical, or physical—that reduce risk and enforce security.
- Access control: Restricts access based on roles or attributes
- Encryption: Protects data in transit and at rest by making it unreadable without a key
- Data classification: Labels data by sensitivity to guide handling and storage
- Audit logging: Records access and activity to support investigation and compliance
- Segmentation: Limits lateral movement by separating data environments
- Monitoring and alerting: Detects anomalous access patterns or usage
Technologies
These are the underlying mechanisms that enable secure data protection strategies and toolsets.
- Public key infrastructure (PKI): Supports encryption, digital signatures, and identity validation
- Transport layer security (TLS): Secures data in motion between systems
- Tokenization: Replaces sensitive data with non-sensitive placeholders
- Federated identity: Enables secure access across systems with shared authentication
- Zero trust architectures: Assume no implicit trust and validate each access request independently
These categories overlap in practice. But separating them helps clarify how data security management is implemented and maintained.
How to manage data security across the full data lifecycle

Data security management isn't a one-time task. It has to follow the full lifecycle of the data. From creation to disposal.
Each stage carries its own risks and requires specific controls to reduce exposure and maintain integrity.
- Identify and classify data: Start by determining what kinds of data your organization collects, creates, or receives. Classify it by sensitivity to guide how it should be protected.
- Assign ownership and handling rules: Define who is responsible for the data. Set clear rules for how it should be accessed, used, shared, and stored.
- Protect data during use: Restrict access using role-based controls. Monitor access behavior to detect misuse. Segment high-risk environments to limit exposure.
- Secure data in transit: Use encryption and secure protocols when data moves across systems, applications, or networks. Validate that transfers only occur through approved channels.
- Encrypt and retain data at rest: Store data securely using encryption, backups, and physical or logical access controls. Apply retention schedules based on legal and operational needs.
- Safely delete or sanitize data: When data is no longer needed, securely delete or sanitize it to prevent recovery. Use tools that ensure data is unrecoverable if media is reused.
- Maintain auditability: Record relevant actions like access, modification, and deletion. This supports accountability, incident response, and compliance.
Lifecycle management only works when each phase is addressed intentionally. Controls need to stay aligned with how and where the data is used over time.
How to implement data security management step-by-step

Data security management isn't just a matter of deploying tools. It's a structured discipline that brings together policies, safeguards, and operational practices.
Here's how to implement it step by step.
Step 1: Define governance and scope
Start by establishing who owns the data security program.
- Identify business objectives, risk tolerance, and legal or regulatory requirements.
- Set the scope based on data types, systems, and environments you need to secure.
- Then formalize ownership and oversight to support long-term accountability.
Tip:
Don't forget to include both technical and business stakeholders in the governance structure. This helps bridge operational gaps and ensures data policies are practical across teams.
Step 2: Identify and classify data
Create and maintain an inventory of the data your organization handles.
- Classify it based on sensitivity, regulatory exposure, or business criticality.
- Use that classification to drive handling rules and protection levels.
- Make sure classification aligns with access control and retention policies.
Step 3: Assess risks and requirements
Evaluate where data is exposed and what could go wrong.
- Include internal threats, third-party risk, and system vulnerabilities.
- Map these risks to specific controls and requirements tied to business needs or compliance standards.
- A strong risk register helps keep priorities focused and defensible.
| Further reading: What Is a Data Risk Assessment?
Step 4: Select controls and define policies
Decide which controls you'll use to mitigate identified risks.
- That includes technical controls like access restrictions, encryption, and monitoring.
- It also includes administrative controls like data handling policies, acceptable use, and retention rules.
- Policies should be practical, enforceable, and reviewed regularly.
Tip:
Prioritize controls that can be enforced consistently across environments. For example, controls that span cloud and on-prem systems reduce complexity and policy drift.
| Further reading:
Step 5: Implement tools and technical safeguards
Choose tools that support your policies and align with your architecture.
For example: DLP for data in motion, encryption for data at rest, and access management tools for role enforcement.
Integrate controls into workflows so protections are automatic, not manual.
Step 6: Monitor, audit, and update
Track how data is used, accessed, and modified.
- Review audit logs, alert on anomalies, and test controls regularly.
- As your environment changes, update controls and policies to reflect new risks or changes in data flow.
- Monitoring should inform not just alerts, but governance decisions.
Tip:
Use monitoring data to identify low-value or unused data assets. This can guide clean-up efforts and reduce exposure by eliminating unnecessary risk surfaces.
People are a critical part of data protection. Make sure roles are clearly defined and that staff understand their responsibilities.
Deliver targeted training and reinforce policies through onboarding, reviews, and corrective action processes. Training should reflect real workflows, not just abstract threats.
Tip:
Reinforce accountability by tracking policy acknowledgment and completion rates. This helps surface gaps in awareness and supports stronger audit readiness.
| Further reading: Top 12 Data Security Best Practices [+ Tips, Tricks, & FYIs]
What frameworks guide data security management?
You don't have to start from scratch when building a data security management program. Lean on well-established frameworks to define goals, select controls, and measure progress.
Note that these frameworks don't all serve the same purpose.
Some offer high-level governance guidance. Others are more operational or control-focused. And some help translate policies into specific technologies or program activities.
But all of the frameworks below serve as the foundation for effective data security management. While each has a different lens, they all help teams stay aligned with risk, regulation, and real-world threats.
| Data security management frameworks | ||
|---|---|---|
| Framework | Primary focus | How it supports data security management |
| NIST Cybersecurity Framework (CSF) 2.0 | Risk-based cybersecurity outcomes | Helps organizations define a target security posture, prioritize actions, and map outcomes across governance, protection, detection, response, and recovery. |
| NIST SP 800-53 Rev. 5 | Security and privacy controls | Provides a catalog of detailed controls used to enforce confidentiality, integrity, and availability across systems, data types, and environments. |
| ISO/IEC 27001:2022 | Information security management systems | Defines how to establish, implement, maintain, and improve a comprehensive ISMS based on risk assessment and treatment. |
| COBIT 2019 | Governance of enterprise IT | Offers a governance framework that connects enterprise goals with IT objectives, including data protection, control objectives, and performance monitoring. |
| CIS Controls v8 | Operational safeguards | Offers prioritized, implementation-focused controls that directly support technical enforcement of data security policies across endpoints, users, and networks. |
Who owns data security management in an organization?
Ownership of data security management depends on the structure, size, and maturity of the organization.
But across most frameworks, the responsibility sits with clearly designated roles tied to risk governance and information security. Not general IT. That distinction matters.
Here's why:
Effective data security requires oversight, authority, and accountability. Which means someone has to be responsible for making policy decisions, allocating resources, and ensuring compliance.
That's typically a C-level or senior leadership role—such as a Chief Information Security Officer (CISO), Chief Risk Officer (CRO), or Chief Data Officer (CDO)—depending on how the organization is structured.
Important:
These roles don't operate alone. Security, risk, legal, compliance, and privacy teams all share responsibilities.
But the ultimate ownership should be formalized. Frameworks we referenced earlier, like the NIST CSF and COBIT, reinforce this by emphasizing defined roles, delegated authority, and continuous reporting on performance and risk posture.
Without that structure, it's easy for accountability to diffuse. Or disappear.
Top 5 common data security management pitfalls
Even with the right tools and policies in place, data security management can still fall short. Small gaps add up quickly. And often show up in the same familiar places.
Success depends on consistent execution across people, processes, and systems.
Here are five common pitfalls that quietly undermine even well-designed data security programs:
1. Incomplete data classification
Failing to accurately classify data is one of the most common weak points.
Without clear labels for sensitivity levels, organizations can't confidently enforce access, encryption, or retention policies.
' stored in a CRM system with 'Moderate' sensitivity marked by an orange dot and classified as 'Internal.' The second row shows 'Social Security #' in a billing platform with 'High' sensitivity indicated by a red dot and also classified as 'Internal.' The third row lists 'Marketing images (unpublished)' in cloud storage with both 'Low' (green dot) and 'Moderate' (orange dot) sensitivity values and a classification of 'Public,' suggesting a mismatch. The fourth row, 'Credit card number' in a support database, has 'High' sensitivity marked by a red dot but is labeled 'Unclassified' and outlined with a red border to highlight the issue. The final row shows 'HR salary records' on a shared drive with 'High' sensitivity marked by a red dot and a classification of 'Confidential.' Below the table, a caption reads: 'Incomplete classification often looks like this—missing values, default labels, or mismatched risk levels.'")
This leaves sensitive information exposed or improperly handled.
2. Overly permissive access controls
It's easy to grant too much access for the sake of convenience. But when users have access beyond what they need, it increases the risk of unauthorized exposure. Especially if credentials are compromised.

Least privilege should be the default.
3. Lack of visibility into data flows
If data flows aren't mapped—especially across third-party providers and cloud environments—it's difficult to monitor or control how sensitive data is stored, processed, or shared.
You can't protect what you don't understand.
4. Stale or unmanaged data inventories
Inventories aren't one-and-done. But many teams don't revisit them regularly.
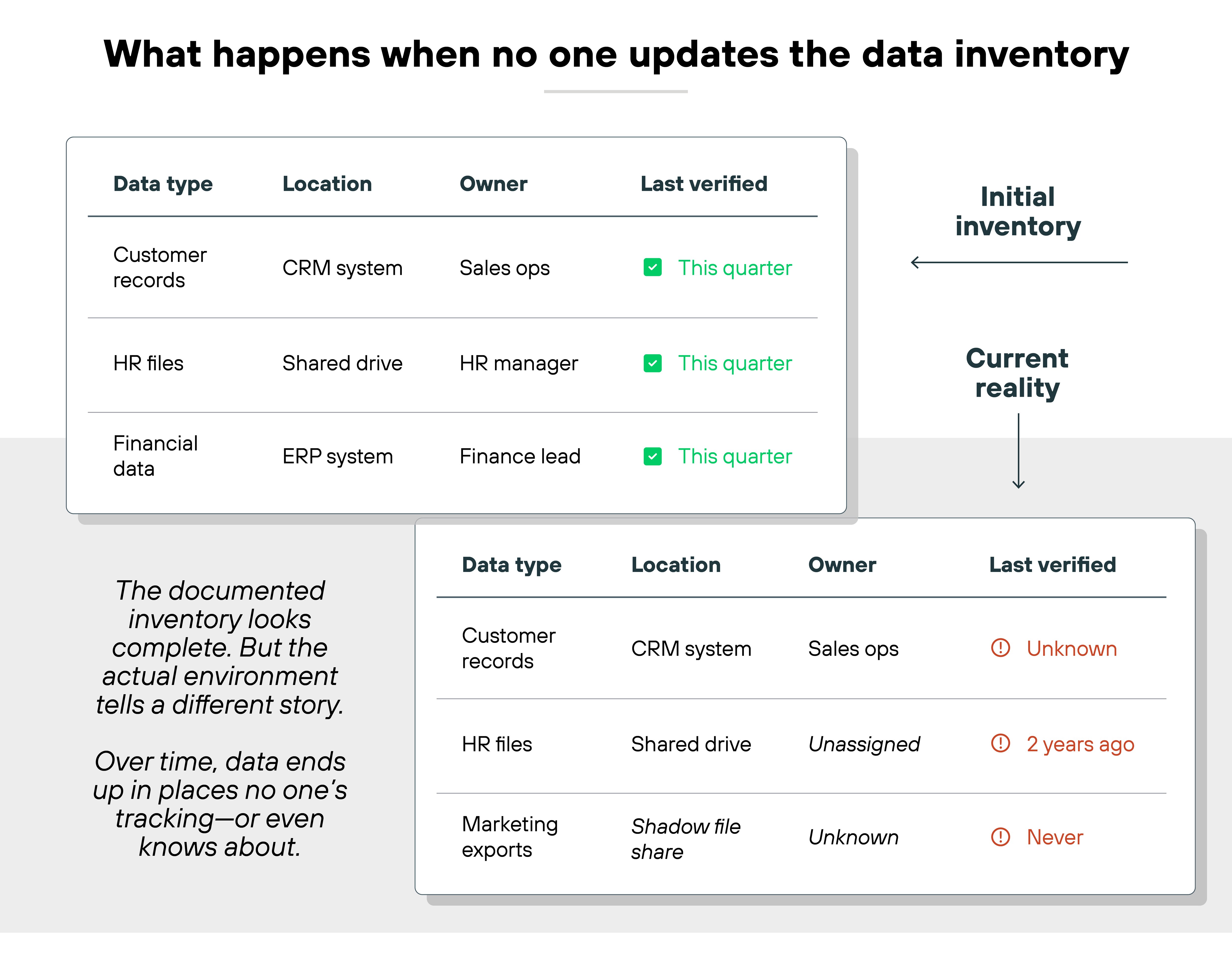
That means outdated mappings, forgotten repositories, or untracked shadow IT. All of which can lead to data loss or noncompliance.
| Further reading: What Is a Data Flow Diagram?
5. Poor enforcement of data retention policies
Retention rules exist for a reason. But without enforcement, sensitive data may be kept indefinitely. Or deleted too soon.

Both increase risk. And neither meets the requirements of most regulatory frameworks.
Comparing data security management, information security management, and cybersecurity management
These three terms are often used interchangeably. But they don't mean the same thing.
Data security management focuses strictly on protecting data. It's concerned with how data is classified, accessed, transmitted, stored, and disposed of, regardless of format or location. The goal is to safeguard data's confidentiality, integrity, and availability.
Information security management is broader. It covers data but also includes the protection of other types of information assets, such as documentation, intellectual property, and business processes. This approach integrates physical security, personnel practices, and technical controls to safeguard organizational knowledge.
Cybersecurity management zeroes in on digital systems and networks. It involves identifying and responding to threats that target IT infrastructure, including malware, unauthorized access, and denial-of-service attacks. While data protection is a part of this, the emphasis is on system and network-level security.
In short: Data security is a subset of information security, which itself overlaps with but is not equivalent to cybersecurity.
GARTNER MARKET GUIDE FOR DATA LOSS PREVENTION
See how today’s data loss prevention solutions compare.
Download reportIt creates a structured, organization-wide approach to protect data throughout its lifecycle. It aligns controls, policies, and accountability to reduce risk, enforce compliance, and support incident response.
Examples include DLP for preventing data leakage, SIEM for monitoring threats, CASBs for cloud enforcement, IdPs for access control, EDR for endpoint protection, and backup tools for recovery.
Data security focuses on protecting data itself. Cybersecurity targets broader threats to systems and networks. Data security is more specific, while cybersecurity includes infrastructure-level protection.
Ownership typically lies with a senior role like a CISO or CRO. Security, risk, compliance, and privacy teams support it. Frameworks recommend formalized authority and clear accountability.
Common issues include incomplete classification, overly broad access, poor visibility, outdated inventories, and weak policy enforcement. These gaps expose sensitive data and increase compliance risk.
Relevant frameworks include NIST CSF, NIST SP 800-53, ISO/IEC 27001, COBIT 2019, and CIS Controls v8. Each supports different aspects—from governance to operational control.